
GEAR:KV cache压缩框架精读
GEAR: 一種高效的近乎無損推理的LLM的 KV cache 壓縮策略
論文地址在這裡GEAR: An Effective KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
研究背景
原文中作者總結了現在階段為了解決GPU Memory問題的流行的幾種方法:
(a)使用offload技術,通過將GPU的內存消耗轉移到CPU使用的內存or
NVMe的存儲空間上.這種方式對總線帶寬(bandwidth)需求極大
(b)緊接著提出來的是tokens dropping技術(比如我們上一篇文章StreamLLM也屬於這一類),這類方法屬於是利用注意力分佈的稀疏性,將註意力分數低下的tokens捨棄達到降低顯存消耗的目的.
(c)另一種經常使用的量化技術(quantization),通過將全精度的數據轉化為半精度的數據進行存儲來降低顯存消耗.
上述的三種方法:(a)會依賴於總線的帶寬來達到GPU和CPU之間高速的數據傳送.(b),(c)兩種方式雖然在絕大部分任務中都能高效的降低顯存佔用,並且對推理效果的損失也極低;但是在復雜的生成式任務中(比如涉及邏輯推理,解決數理問題)這兩種方法都存在普遍且明顯的效能損失.
在較為簡單的任務中,模型只需要產生少數tokens從少數特定的上下文中就可以完整正確的自回歸任務.然而,在複雜的任務中,通常需要模型依據大量相關的上下文tokens產生更長更多的tokens;然而自回歸的docode過程中每一步得會累積誤差;
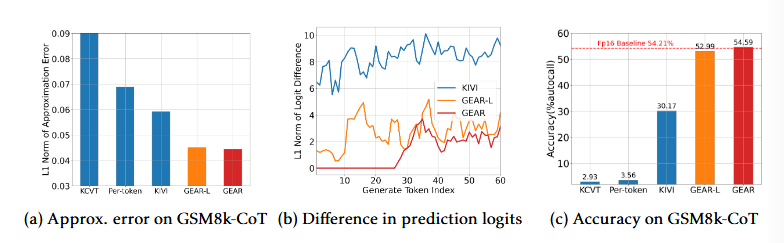
積累的GEAR用來減少KV
cache量化的估計誤差.
深入分析GEAR細節
前置知识
- 基础量化方法
比如说我们有一个tensor
其中
- MHA 多头注意力机制
关于多头注意力的分析前面的文章以及分析过不少了,这里仅给出形式化的公式:
GEAR的總體框架
GEAR的整體思路其實很簡單,主要可以描述為以下三步:
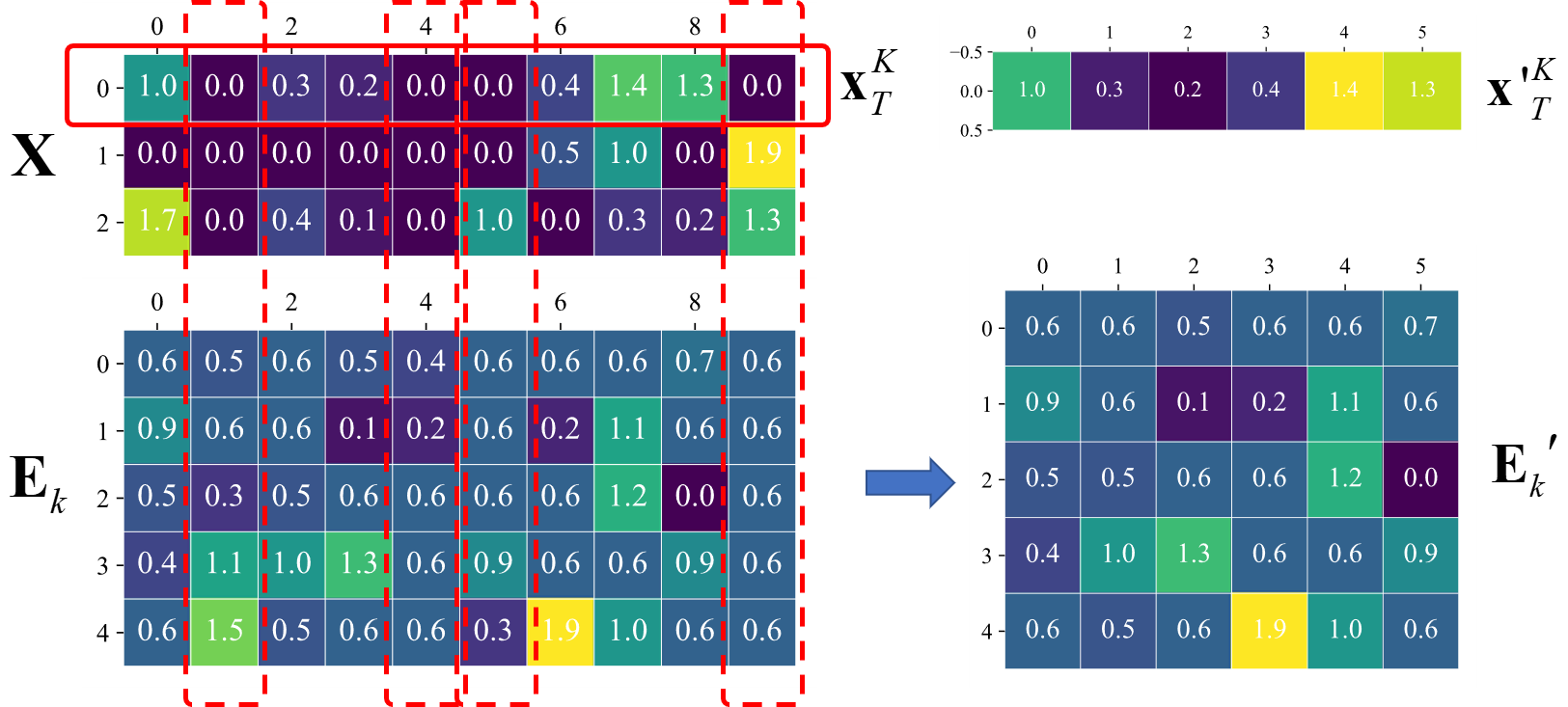
首先對KV cache採用一個常規的量化方法(比如將全進度float16的kv值全部轉儲為int2的類型),但是這必然會導致精度的大幅降低.
然后引入一个低秩矩阵来高效的估计量化之后的残差;
最后再引入一个稀疏矩阵来补全一些异常值导致的极个别的大额误差;
省流版: 在原来粗暴量化的基础上,整体绝大部分的误差是通过引入一个低秩矩阵来解决的,而一些异常值是通过一个稀疏矩阵来恢复的;
- 符号规定:
量化之后的kv cache矩阵为
- 基本策略:
给定一个待处理的tensor
- 我们都知道过大或者过小的异常值会对量化过程的精度造成极大的影响,所以最佳的策略是在量化之前先进行一次异常值提取, 具体而言:
在异常值提取完成之后,再接着进行量化处理:
这样的思路其实在之前早已被应用于LLM的权重量化上, 但是相比于对于权重(weight)量化而言, kv cahce拥有更多的 异常值(outliers),使得异常值提取的重要性更大了;
- 提取完成异常值之后再进行低秩矩阵误差估计;
根据上文的说法, 我们定义的低秩残差为
然后我们将上述低秩残差分作
设
附錄
(a)理解低秩矩陣和稀疏矩陣
低秩矩陣和稀疏矩陣
的相同点在于都表明矩阵的信息冗余比较大.具体来说,稀疏意味着有很多零,即可以压缩;低秩意味着矩阵有很多行(列)是线性相关的.low
rank matrix和稀疏矩陣各有各的用途.
- 補充知識點1 稀疏表示!
假設有
這裡的
針對上述問題,我們可以先選取一組稀疏表示的初始解:
然後的優化目標變成了:
這裡存在
假設我們固定了稀疏表示
上式中
但是這裡仍然需要註意的問題是,我們不能直接使用
參考資料稀疏表示
- 補充知識點2 低秩(low rank represent
低排名🐻❄️)表示!
假設一個輸入信號
然而,矩陣rank的計算和L0范數通常是非凸的,考慮到這點我們通常使用矩陣的核范數
從而得到一個凸優化問題.
(b)稀疏子空間聚類(Sparse Subspace Clustering, SSC)
稀疏子空間聚類問題(SCC)可以描述為: 假設有一組高維數據點的集合稀疏向量
和上面低秩表示一樣我們定義一個鬆弛化的SCC最小化函數
上式意味著我們在整體數據集上為每一個數據點尋找一個盡可能稀疏的表述法則,從而將數據進行聚類.


Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .




