
SteamingLLM
只会开新坑不会填旧坑的屑Mr.Xau🕊️🕊️🕊️ 又打算分享一篇基于KV
Cache优化经典工作
本人近期任务太多以后一定会填坑的(下次一定
🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺
🤓🤓🤓🤓🤓 已填坑完成! 🤓🤓🤓🤓🤓
StreamLLM 基于注意力汇聚现象的KV Cache策略
论文地址,Streaming这个词很有意思,不是我们玩的steam
,它可以是喷射的意思,也可以是涓涓细流的意思;我觉得从这篇工作的内容来看,翻译为娟娟溪流可能更加合适一点。那么这个娟娟细流到底指的是LLM中的什么,但是正所谓铁打的衙门流水的官,KV
Cache中有没有铁打不变的东西呢?且听后文分析。
知识补充
主要是KV Cache的介绍:什么是KV Cache,为什么只缓存KV?
什么是KV Cache?
回忆一下Transformer中的注意力机制,在经典的Transformer中我们有向量化的语料输入Tokens序列
我们通过这个编码之后的
我们把
如果采用仅解码器的架构,由于掩码的存在,会有:
我们都知道每次LLM会将上一次输出的一个token放在下次输入的最后一个,那么下一轮的注意力分数是:
显然因为掩码的存在,注意力分数变成了一个下三角矩阵,因此当我们产生了新的tokens的时候,只需要计算最新tokens的q查询向量
从上面的公式的形状,我们也不难发现,完全没有必要缓存
KV Cache有什么问题
随着输入序列的增加,如果缓存所有的
这篇工作为什么叫StreamLLM,我的理解是因为即使随着对轮对话的进行,上下文越来越长,StreamLLM也能够基于注意力汇聚这一现象合理的关键的初始和一定上文窗口的cache来使得即使上下文增长也能像涓涓细流一样稳定流畅的推理。
StreamLLM 的原理
一些解决方式的对比🥵🥵🥵
为了解决上文中提及的KV cache“爆炸”的现象,我们对比一些cache的策略:
(a)最原始的解决“Dense Attention”
所谓dense attention就是将所有的KV键值对全部存储起来
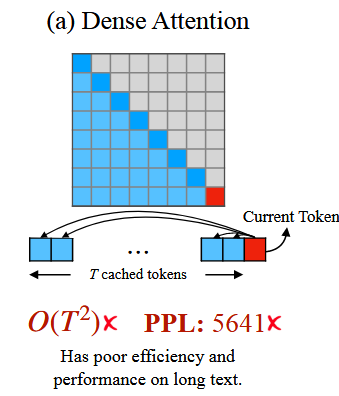
这样存储不仅整体运算时间会达到
(b)自然而然想到的“windows attention”窗口注意力机制
所谓窗口注意力机制即只缓存窗口长度为L的K值,如下图所示:
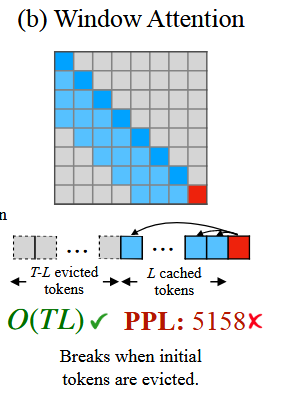
这种窗口注意力机制能够将计算量降至
(c)滑动窗口注意力机制“slide attention”
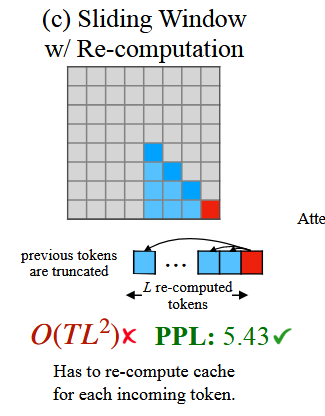
所谓滑动窗口注意力的计算复杂度
StreamingLLM 技术和表现
文中提出的StreamingLLM技术,保留了“下沉注意力”部分,又结合了最近的几个token的K值,就像下图所展示的一样。
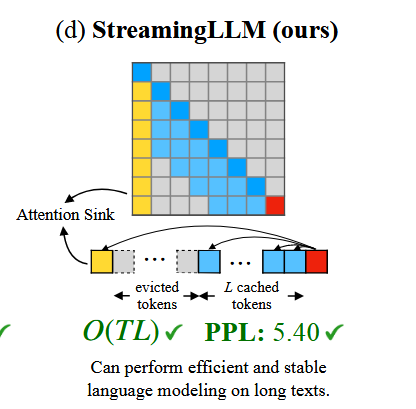
注:文中所说的保留“下沉注意力”是为了注意力分数的稳定计算。
关于为什么会出现“注意力下沉”,以及为什么注意力下沉会出现在初始的token上,一种直观上的解释是:
有很多token其实和前文关系都不大,但是在softmax操作中的归一化操作又必须保证注意力分数加和等于1; 并且这其中又恰好只有初始的token才能被绝大多数后面的token看到. 所以直观上注意力分数就应当会下沉于初始的token上;
基于这些想法,我们就可以设计一个在有限窗口长度上训练的LLM有效的用于无限文本输入。
实验验证 “attention sink” 现象
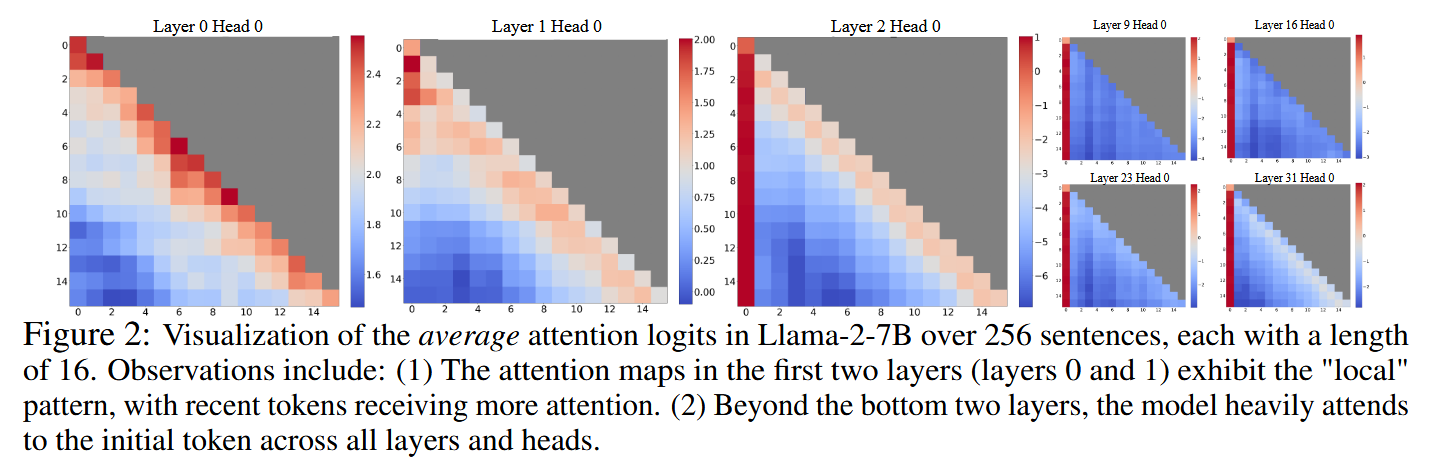
如下图所示,下图是256个句子在LLaMa-2-7B上测试的平均注意力分数的热力图;很明显,注意力分布主要集中于recent tokens以及注意力下沉的initial token;
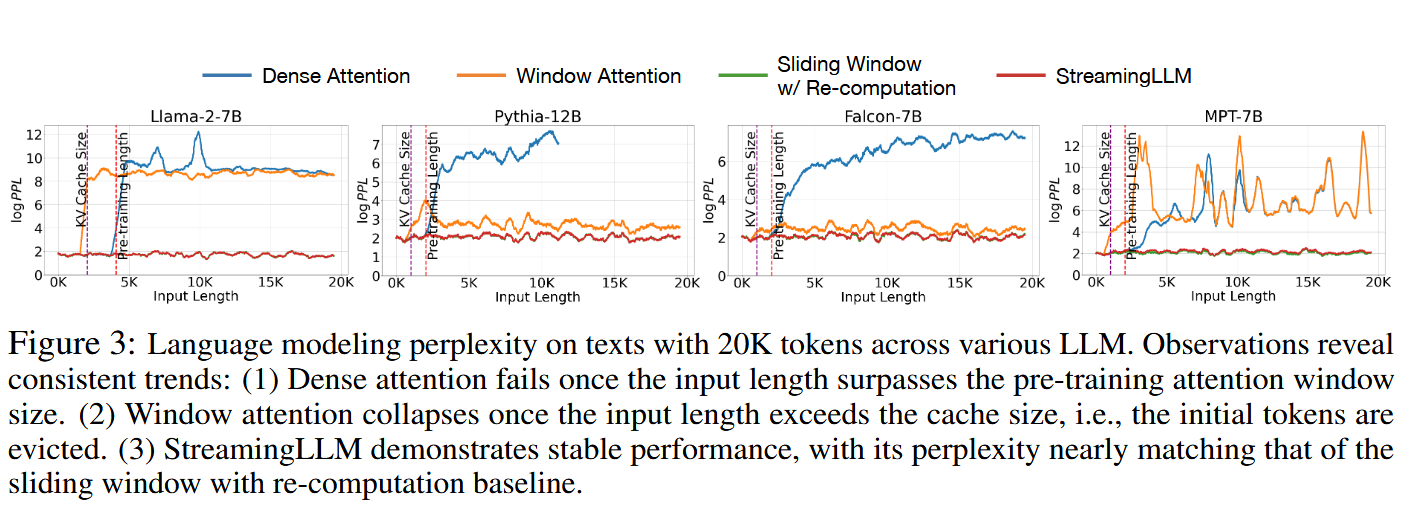
以及在不同LLM上对不同策略的PPL测试结果:
蓑鱿剪切线
进一步探讨为什么窗口注意力会出现性能崩溃🧐🧐🧐
在上图中已经展示过,当输入文本长度超过KV Cache的长度之后,PPL会出现激增现象。这恰好又从反面印证了:无论initial tokens距离当下的token距离有多远,他们对当下token注意力分数的影响都是重要的。
从softmax函数的特性说起
为什么initial token如此重要比较直观的,考虑softmax函数:
如果直接移除initial token,也就是公式中的
initial tokens重要的原因?语义信息or绝对位置?
设计一个对比实验,将原本文本的initial tokens全部替换成"\n",会导致什么后果?

结果并不出乎意料:替换之后的initial tokens依旧维持着高注意力分数,这意味着并不是initial tokens的语义信息让它们如此重要,它们重要的原因在于它们的初始的绝对位置。
一些附加实验
同样,作者还探究了initial tokens数量的选取对LLM效果的影响。
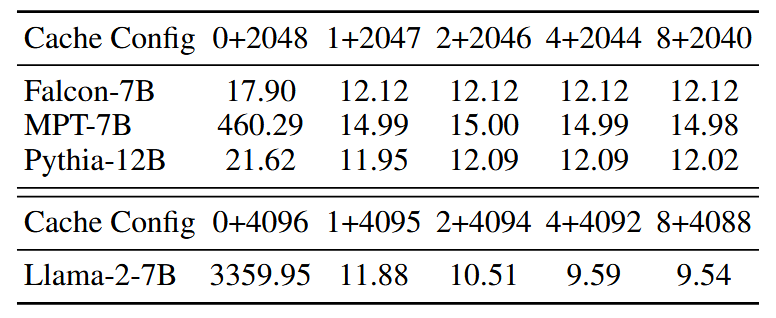
不难发现选取1、2个initial tokens有时并不足以完全恢复LLM的效果。作者推测这是由于训练时候的预料并没有选取固定的开头前缀所导致的必然后果。
可能的替代解决方案 softmax_off_by_one函数
通过前文通篇的分析,我们不难得知:softmax函数的特性倾向于将注意力分数分配给全局可见的initial tokens,基于这点出发我们可以考虑将softmax进行改进,将其改写为:
这样改写等价于我们蓄意将一部分注意力分数提前拿出来进行sink。
附录
to be continue


Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .




