
LLM剪枝-SparseGPT方法
'SparseGPT' one-shot Pruning Strategy
【论文地址】SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot
SparseGPT简介
SparseGPT是一种用于压缩Massive
LLM的一次性(one-shot)、无须重训练(no need for
retraining)的基于非结构化Pruning(剪枝)的模型压缩方法,发现了至少50%的稀疏性;
SparseGPT提出的创新点何在?其实就是两点:ONE-SHOT&&NO RETRAINING;
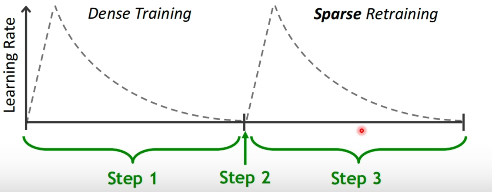
上图就是原来的模型减枝之后,我们仍然需要一个Sparse Retraining的过程来调整稀疏化之后的模型,SparseGPT提出的剪枝方法则是one-shot的,也就是无须后面retraining或者说调整的代价很小。
SparseGPT的基本原理
已有方法存在的问题:
一般的模型减枝(Pruning)都包含两步——Mask Selection 和 weight restruction。
假设我们某一层的模型权重记作
但是因为
根据上述分析和推导,我们的权重重建过程可以化为一个最小二乘法的最优化问题,形式通解可以描述为:
我们不妨定义海森矩阵:
这里面的
但是这样的方法仍然会存在很多问题:
- 最重要的一点是:掩码每一行不同会导致不同的海森矩阵,导致计算量巨大。并且
,计算矩阵的逆也十分消耗计算资源,就像下图所展示的这样。
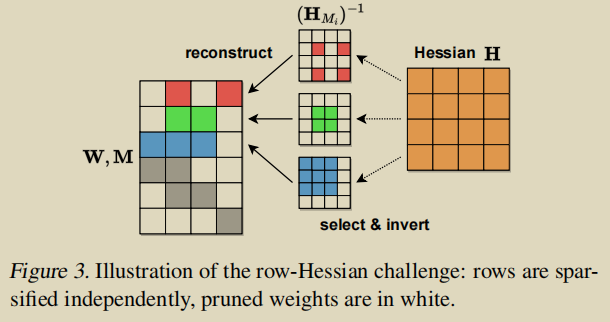
基于OBS思想的权重重建
一种等价的迭代视角
作者借鉴了Optimal Brain Surgery【OBS】(相关介绍见附录部分)中调整剩余权重来减少Pruning所减去当前权重影响的思想来对现有的方法进行改进。但是相比较于原来OBS更改全局参数的策略,SparseGPT则是使用一种更加高效的方法,每次只更新未被Pruning掉的部分;
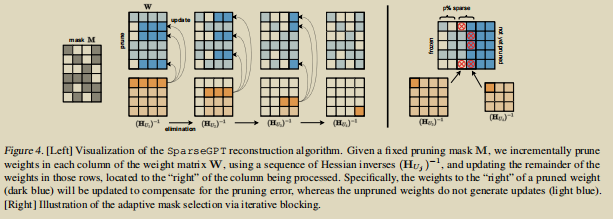
上图就是 SparseGPT
Pruning算法的可视化,每次对一列权重进行Pruning(白色的块是被减掉的),右侧深蓝色的块就会被参数更新来补偿修建错误。没被修改的块就不会对后续参数造成影响。
工作亮点:
1)海森矩阵的处理
我们将输入的特征矩阵来进行编号
也就是说
根据这篇论文的工作,我们选取依次少选取一行的优势就显示出来了,我们计算海森矩阵的逆可以根据上一步的逆很快的得到。
设
相比于原来
2)计算复杂度分析
通过上述的分析我们可以看到整体的计算开销主要由三部分组成:
- (a)初始Hessian矩阵的计算
,其中n是输入特征向量的数量; - (b)计算初始Hessian矩阵的逆
; - (c)然后对每一行使用权重重建
总结:总共的时间复杂度就是
自适应掩码选择
在此之前,我们主要集中于谈论权重重建的细节,都是基于一个固定的Pruning
Mask来进行的权重重建。已有的Mask
Selection方法可以参考基于幅度(magnitude)选取的方法;一个最直观地做法就是选取每一列值最小的
为了解决这一点所存在的问题,原文使用了一种叫做迭代阻塞(iterative
blocking)的方法。相比于每次选取一列来做一个
同时SparseGPT稀疏化方法同样可以适用于很多半结构化稀疏性,例如很有名的n:m细粒度结构化稀疏性,所谓N:M细粒度结构化稀疏即在M个连续的权重值中固定有N个非零值,其余元素均为零值,例如下图中N=2,M=4的N:M稀疏(2:4稀疏)。N:M稀疏的权重矩阵可以进行压缩存储,仅保留所有的非零元素,再辅以一个indices矩阵指示非零元素在原矩阵中的空间位置。从实验结果上来看,采用N:M细粒度结构化稀疏方案的模型在权重存储量和计算量大减的同时取得了比肩甚至超过稠密的原网络的推理精度。
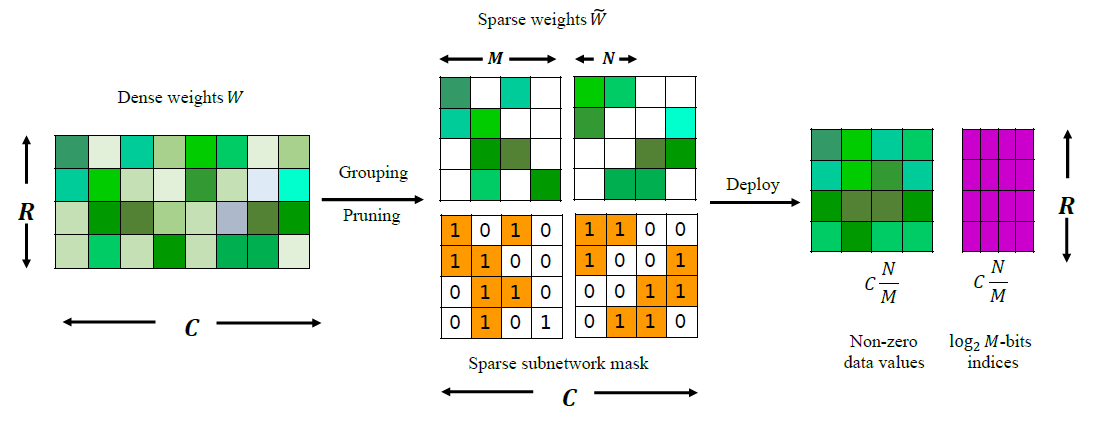
至此我们可以就更具给定的
整体的算法流程可以描述如下:

实验验证部分
- 硬件条件:单块80G A100显卡
- 模型:BLOOM-176B 、OPT-175B系列模型(都是decoder-only的架构)
- 衡量指标:Perplexity困惑度【见附录】
- 测试数据集:raw-WiKiText2、PTB、C4
- Sparsify时间:4h左右
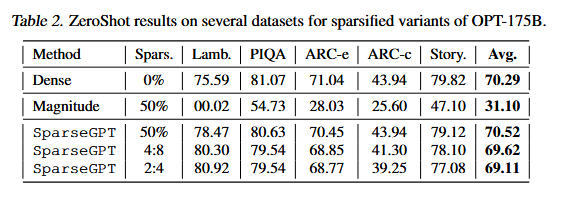
SparseGPT和幅度剪枝效果对比
可以发现,SparseGPT算法能够提供更多的稀疏性:
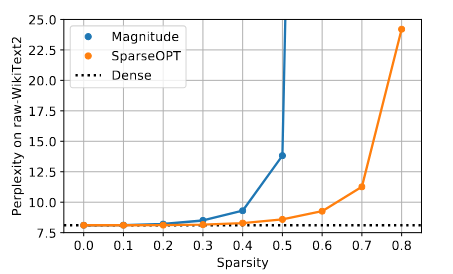
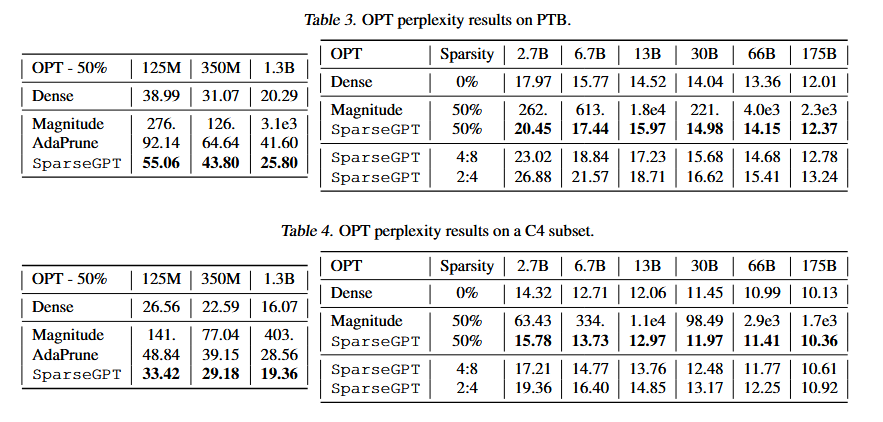
实验结果表明:相比于规模性对较小的视觉任务的模型,LLM在50%的sparsity的设定下,幅度减枝(magnitude pruning)效果下降更加明显。但是对于SparseGPT而言,这种趋势相对平缓许多,对于2.7B的模型,Perplexity的下降已经接近一个百分点,到175B的模型时,下降已经接近于0;
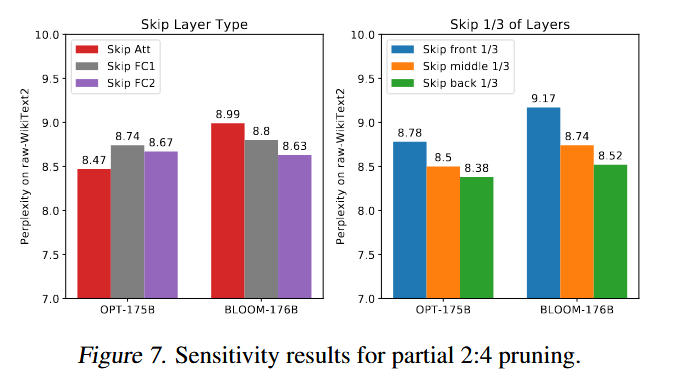
另外对于模型不同部位稀疏化影响敏感性的研究:
later layers are more sensitive than earlier ones
Appendix
结构化剪枝VS非结构化剪枝技术
常见的稀疏方式可分为结构化稀疏和非结构化稀疏。前者在某个特定维度(特征通道、卷积核等等)上对卷积、矩阵乘法做剪枝操作,然后生成一个更小的模型结构,这样可以复用已有的卷积、矩阵乘计算,无需特殊实现推理算子;后者以每一个参数为单元稀疏化,然而并不会改变参数矩阵的形状,只是变成了含有大量零值的稀疏矩阵,所以更依赖于推理库、硬件对于稀疏后矩阵运算的加速能力。
半结构化剪枝是一种介于结构化剪枝和非结构化剪枝之间的剪枝方法,可以同时实现高精度和结构正则化。半结构化剪枝通常基于特定的模式进行剪枝,这些模式可以是任意的,但需要经过精心设计以减轻性能下降并实现特定的加速效果。半结构化剪枝可以被视为一种细粒度的结构化剪枝方法。
参考阅读资料
OBS:‘optimal brain surgery’ 的介绍:
OBS这个名字很有意思,翻译过来就是最佳脑外科手术的意思;很贴合OBS对神经网络所做的事情:他将神经网络中一些不重要的权重、连接给切除之后,再对其他权重做调整来最小化减去神经的损失,OBS这个名字非常切合。
我们考虑对神经网络的误差函数进行泰勒展开可以都得到:
其中
我们可以通过一些梯度下降优化算法来找到一个局部最小解,上述公式第一项就等于0,再忽略三阶无穷小,可以得到:
这个时候我们开始对较小的权重进行减枝,比如我需要剪切权重中的第
其中
由上述的推导,我们现在将问题转化为了一个带约束条件的最优化问题,写出拉格朗日方程:
解这个拉格朗日方程我们可以得到:
Perplexity in LLM
困惑度在LLM中的定义是:
也就是说,在LLM中困惑度(Perplexity)被定义为一个token概率序列的指数平均负对数似然估计。
困惑度越高说明每次产生下一个单词时候选词概率越平均或者说候选词更多。如果用困惑度来衡量一个LLM的表现,那么自然是困惑度越低LLM的表现越好。
后记
这篇文章真的很厉害,特别是每次OBS更新只选取部分子集进行更新,从而大量简化逆矩阵的运算量真的让人印象深刻!impressing!!!

什么时候我才能写出这样的文章😶🌫️😶🌫️😶🌫️
参考资料:
- https://www.cnblogs.com/sasasatori/p/17809829.html

Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .




