
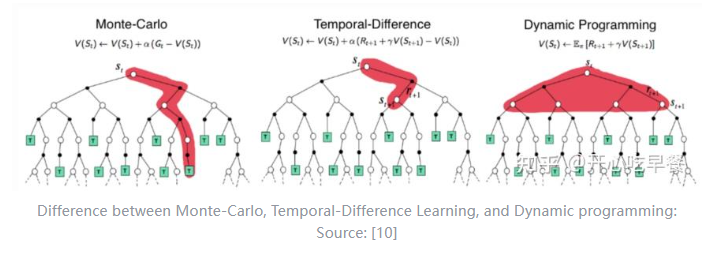
强化学习基础
强化学习入门教程
名词解释
价值函数
在马尔可夫奖励过程中,一个状态的期望回报(即从这个状态出发的未来累积奖励的期望)被称为这个状态的价值(value)。所有状态的价值就组成了价值函数(value function). 于是我们可以将价值函数形式化的定义为:
展开可以得到:
根据马尔科夫概率转移过程我们可以将上面的式子改写为:
贝尔曼方程(Bellman equation)
若一个马尔科夫奖励过程一共有
将所有状态的价值表同样表示为一个向量的形式:
同理将奖励函数写成一个列向量:
于是我们可以将Bellman方程写为:
简记为:
可以直接求得解析解:
上述计算式的计算复杂度是
马尔科夫决策
之前讨论到的马尔可夫过程和马尔可夫奖励过程都是自发改变的随机过程;而如果有一个外界的“刺激”来共同改变这个随机过程,就有了马尔可夫决策过程(Markov
decision
process,MDP)。我们将这个来自外界的刺激称为智能体(agent)的动作.
MDP可以由于一个五元组
to be continue
经典强化学习策略
REINFORCE-基于策略梯度的强化学习算法
我们记一个马尔科夫序列
在策略梯度中,策略经常用一个带参数集
使用梯度上升策略来更新策略参数
其中:
而且其中又满足:
对上式对数求导:
于是有:
REINFORCE算法中的
Actor-Critic 算法
在上述REINFORCE算法里面我们可以将
其中
, 一条采样的总回报; , 采取动作 之后的回报; , 基准线版本的改进; ,时序差分残差;
这个效应,
比如...
提到 REINFORCE
通过蒙特卡洛采样的方法对策略梯度的估计是无偏的,但是方差非常大。我们可以用上述形式引入基线函数序列结束后进行更新,这同时也要求任务具有有限的步数,而
Actor-Critic
算法则可以在每一步之后都进行更新,并且不对任务的步数做限制。
Actor-Critic 算法顾名思义就是将强化学习算法分为两部分:
- Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于判断在当前状态什么动作是好的,什么动作不是好的,进而帮助 Actor 进行策略更新。
对于单个数据定义的如下的价值函数的损失函数:
和DQN中一样,我们将上述
- Actor 要做的是与环境交互,并在 Critic 价值函数的指导下用策略梯度学习一个更好的策略。
所以我们的Actor-Critic算法可以描述为:
初始化策略网格参数
以及价值网格参数 使用当前的动作策略
采样agent轨迹得到 : 为每一步数据计算
更新价值网格参数
根据更新之后的价值网格参数来更新策略网格参数
TRPO算法
之前提到的两种基于策略的算法,在实际训练过程中极易出现训练不稳定的情况;
具体回顾一下基于策略的算法策略:
假设
基于策略的方法的目标就是找到最优的
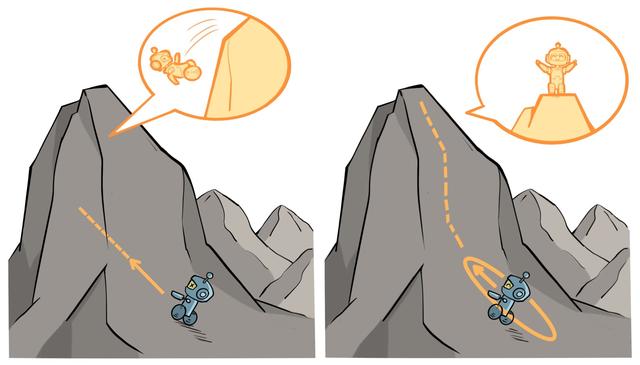
但是这种算法有一个明显的缺点:当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果。
针对以上问题,我们考虑在更新时找到一块信任区域(trust region),在这个区域上更新策略时能够得到某种策略性能的安全性保证,这就是信任区域策略优化(trust
region policy optimization,TRPO)算法的主要思想。
具体来说考虑到初始状态
基于上述推导,我们可以得到新旧策略之间目标函数的差异:
如若定义残差函数:
注意看
我们定义:
于是我们的优化目标为:
进一步处理:
此外为了保证新旧策略足够接近,TRPO 使用了库尔贝克-莱布勒(Kullback-Leibler,KL)散度来衡量策略之间的距离.于是整体的优化公式修改为:
这里的不等式约束定义了策略空间中的一个 KL 球,被称为信任区域。在这个区域中,可以认为当前学习策略和环境交互的状态分布与上一轮策略最后采样的状态分布一致,进而可以基于一步行动的重要性采样方法使当前学习策略稳定提升。
PPO算法
介绍的 TRPO 算法在很多场景上的应用都很成功,但是我们也发现它的计算过程非常复杂,每一步更新的运算量非常大。于是,TRPO 算法的改进版——PPO 算法在 2017 年被提出,PPO 基于 TRPO 的思想,但是其算法实现更加简单。
让我们回忆一下TRPO的优化目标:
TRPO 使用泰勒展开近似、共轭梯度、线性搜索等方法直接求解。但 PPO 用了一些相对简单的方法来求解。具体来说,PPO 有两种形式,一是 PPO-惩罚,二是 PPO-截断,我们接下来对这两种形式进行介绍。
PPO-惩罚算法
PPO-惩罚(PPO-Penalty)用拉格朗日乘数法直接将 KL 散度的限制放进了目标函数中,这就变成了一个无约束的优化问题,在迭代的过程中不断更新 KL 散度前的系数。即:
设
- 如果
,那么 . - 如果
,那么 . - 否则
.
其中,
PPO截断
PPO 的另一种形式 PPO-截断(PPO-Clip)更加直接,它在目标函数中进行限制,以保证新的参数和旧的参数的差距不会太大,即:


Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .




