
最近想和大家讲讲`diffusion model`!
Diffusion和图像生成的关系
谈到diffusion model那么就不得不谈及AIGC.
在过去几年里里,以Stable
Diffusion为代表的AI图像/视频生成是世界上最为火热的AI方向之一. Stable
Diffusion里的这个”Diffusion”是什么意思?其实,扩散模型(Diffusion
Model)正是Stable Diffusion中负责生成图像的模型。想要理解Stable
Diffusion的原理,就一定绕不过扩散模型的学习。
在这篇文章里,我会由浅入深地对去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPM)进行一个介绍。
图像生成任务的解决
相比其他AI任务,图像生成任务显然是一个更加困难的事情. 比如人脸识别,序列预测...这一系列任务都有明确的训练集来给出or蕴含一个[标准答案]. 但是图像生成就没有, 图像生成数据集里只有一些同类型图片,却没有指导AI如何画得更好的信息。
过去的解决方案:
GAN对抗生成模型
GAN的原理简介
GAN的主要结构,包括一个生成器G(Generator)和一个判别器D(Discriminator),整个训练过程,便是二者的对抗博弈:
给定参考数据集
它的含义其实就是: 对于生成模型
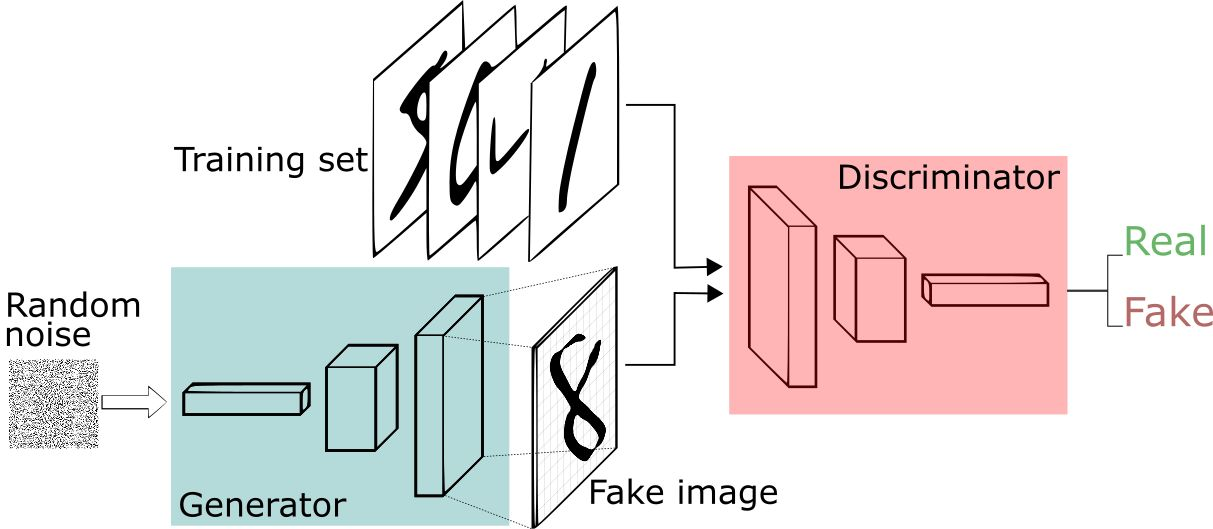
GAN存在的问题:
(*) 无法用于解决离散型数据的生成问题,
自然语言处理是一个很典型的例子:
局部信息很重要:图像局部很多细节并不太影响人类的对图像的理解,只要整体到位就
ok,不然也犯不着 CNN 这么多 filter
一层层给你过滤,你破坏少数像素点不影响人类理解。自然语言麻烦在于,在细微处修改一下,就变味了。比如“西瓜汁好喝!”,我稍微改一下“西瓜汁好喝吗?”,尾巴动一点,整个意思都变了。GAN
局部信息重构到底是靠死记硬背训练样本,还是靠神经网络插值“生成”出来的?我反正不清楚,不管如何,针对自然语言这种细节敏感的问题,GAN
不是一个首选方案,不然 n-gram 的 LM 也不会活到今天。
- 解决办法(引入强化学习RL)
related works SeqGAN
to be continued
VAE
(Variational AutoEncoder) 变分推断模型
VAE作为可以和GAN比肩的生成模型,融合了贝叶斯方法和深度学习的优势,拥有优雅的数学基础和简单易懂的架构以及令人满意的性能,其能提取disentangled latent variable的特性也使得它比一般的生成模型具有更广泛的意义。
- 关于
Latent Variable(隐藏变量)的理解
生成模型一般会生成多个种类的数据,比如说在手写数字生成中,我们总共有10个类别的数字要生成,这个时候latent variable model就是一个很好的选择。
为什么呢?举例来说,我们很容易能注意到相同类别的数据在不同维度之间是有依赖存在的,比如生成数字5的时候,如果左边已经生成了数字5的左半部分,那么右半部分就几乎可以确定是5的另一半了。
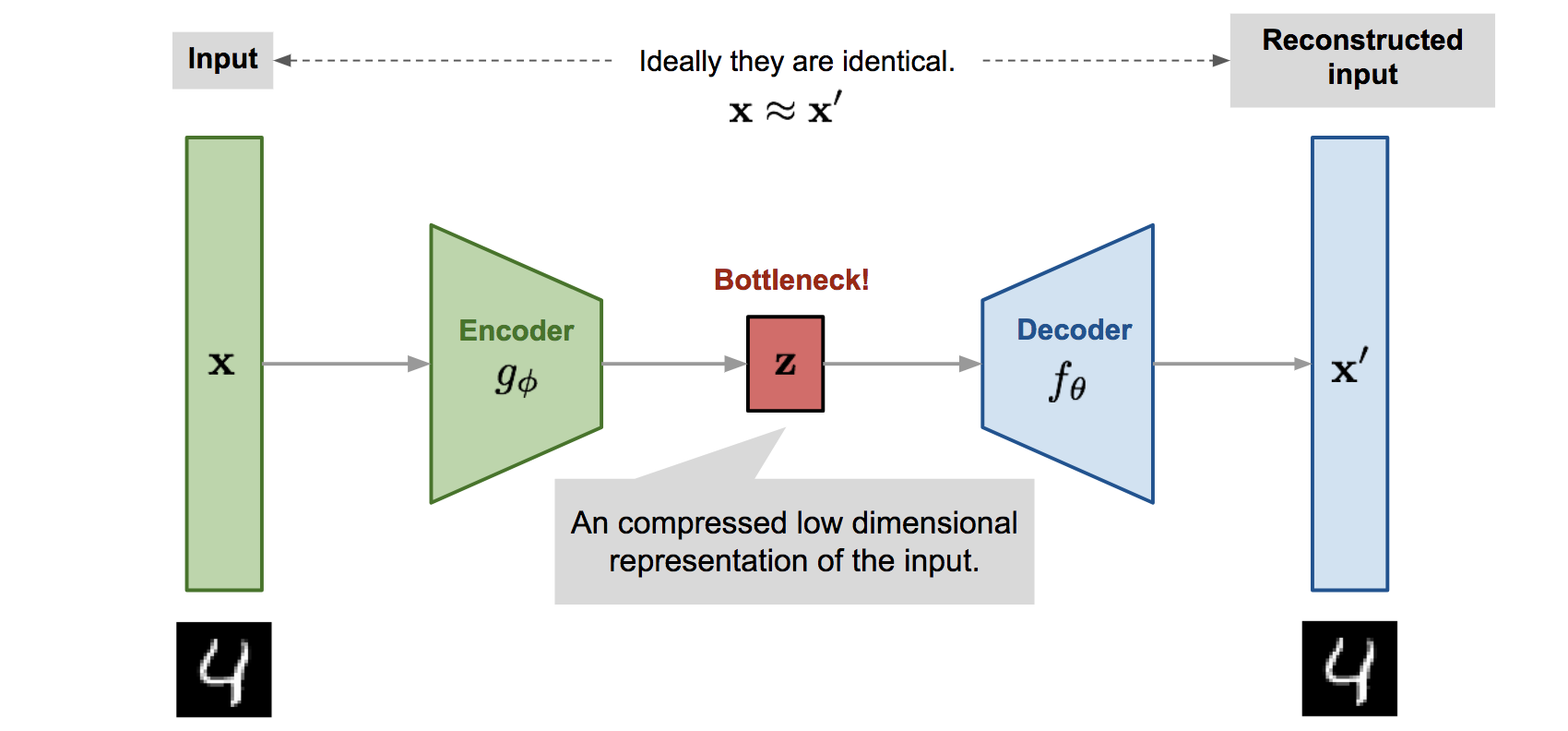
因此一个好的想法是,生成模型在生成数字的时候有两个步骤,即(1)决定要生成什么数字,这个数字用一个被称为latent variable的向量z来表示,(2)然后再根据z来直接生成相应的数字。用数学表达式来表示就是:
- 问:那么现在的关键是关于
Latent Variable的 先验概率分布形式 如何取值?
答:很简单,直接设定 标准高斯分布就行.
因为任何复杂的分布都可以通过多层MLP映射成标准高斯分布.
- 问: 如何训练一个VAE
答: 最大化
- 有了
的先验分布知识,我们可以使用若干次采样来最大化 似然函数
即最大化
然而当z先验分布来训练低效的原因直觉上是很明显的.因为对于数据集中的一个实例
decoder训练,这样有效训练次数将大幅提升!
或者换一种说法: 我们需要注意到, 对于采样
那么问题来了, 怎么计算 很难的!

- 贝叶斯公式巧妙转换
直接得到后验分布 encoder侧的输出 encoder的输出 KL散度来衡量:
使用贝叶斯公式对上式化简化繁:
(其实贝叶斯这一步是最关键的一步)
可以看见:我们通过使用贝叶斯公式将
巧妙地转换为 将问题从 encoder一侧转移到decoder一侧 ! 这是最最关键的一步!
于是:
再度化简可以得到
注意到KL散度的非负性,于是有:
我们不妨记作:
ELBO(Variational Lower
Bound)记作变分下界;至此,我们近似将问题转化为了最大化变分下界;
既然目标是让变分下界最大化,那么我们就需要仔细研究一下这个变分下界。
首先是第一项,要想最大化 ELBO,那我们自然是想让第一项尽可能的大,也就是 x given z 的概率分布期望值更大。这很明显就是由 z 到 x 重组的过程,也就是 AutoEncoder 中的 Decoder,从潜在空间 Z 中重组 x。模型想做的是尽可能准确地重组.
其次是第二项,要想最大化 ELBO,我们自然需要让这项 KL 散度尽可能小,也就是 潜在空间 z 的近似后验分布尽可能接近于 z 的先验分布!这一项我们可以理解为,模型想让 z 尽可能避免过拟合.
Diffusion模型
扩散模型是一种特殊的VAE,其灵感来自于热力学:一个分布可以通过不断地添加噪声变成另一个分布。放到图像生成任务里,就是来自训练集的图像可以通过不断添加噪声变成符合标准正态分布的图像。但是:
不再训练一个可学习的编码器,而是把编码过程固定成不断添加噪声的过程;
不再把图像压缩成更短的向量,而是自始至终都对一个等大的图像做操作。解码器依然是一个可学习的神经网络,它的目的也同样是实现编码的逆操作。
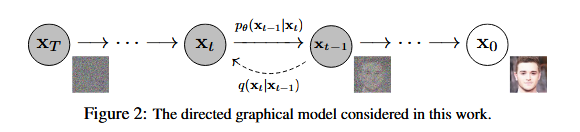
具体来说,扩散模型由正向过程和反向过程这两部分组成,对应VAE中的编码和解码。在正向过程中,输入
PART1 加噪过程:
前向加噪过程可以用描述为:
其中
不妨设
其中
再进一步:
这意味着
加噪过程到此结束.
PART2 解噪过程
实际上, 每一步降噪过程
于是有:
注意到(贝叶斯公式又立大功):
Markov过程,后一个状态只取决于前一步状态.
再次注意到:
整理得到:
其中:
我们
于是模型预测的
PART3 训练过程
diffusion本质上是一种特殊的VAE model于是我们可以参考VAE变分推断的变分下界将问题进行转换:
进一步处理可以得到:
注意到加噪过程
根据多元高斯分布的KL散度求解公式:
代入:
即可进行计算求解训练!
光速进行一个条件化生成的介绍:
作为生成模型,扩散模型和VAE、GAN、flow等模型的发展史很相似,都是先出来了无条件生成,然后有条件生成就紧接而来。无条件生成往往是为了探索效果上限,而有条件生成则更多是应用层面的内容,因为它可以实现根据我们的意愿来控制输出结果。
从方法上来看,条件控制生成的方式分两种:事后修改(Classifier-Guidance)和事前训练(Classifier-Free)。对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的Classifier-Guidance方案;
Classifier-Guidance 条件控制方法
无条件生成可以形式化描述为
由于
因此有:
可以看到在经过一系列处理之后, 相比于原来无条件生成,仅仅多出来


Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .




