
一个attention降秩理论的证明
Attention is not all you need? 纯粹的注意力机制有什么问题?
论文地址-> pure attention loses rank doubly exponentially with depth <-
简介
原文链接如上所示,论文开门见山的提出来一个新观点:纯粹的注意力机制会导致矩阵的秩指数级别的下降;论文标题也很有意思Attention is not all you need,则是与LLM的开山之作Attention is all you need相呼应,这篇文章看似在挑战attention机制,实际上是在从一个全新的角度来阐述为什么attention为什么会表现优异。
回忆一下multi-head attention机制的细节:
一个通俗且不严谨的科普(为了不懂NLP的观众):在自然语言处理过程中,我们将每个word编码为一个vector(我们认为这个向量几何意义上会反映单词的语义信息,你可以理解为比如原神和崩坏铁道的向量表示相对距离更近、而和明日方舟更远,因为后者非米哈游产),从而单词组成的句子就会变成一个matrix。自然语言处理中有很多模块负责理解并处理这些matrix.
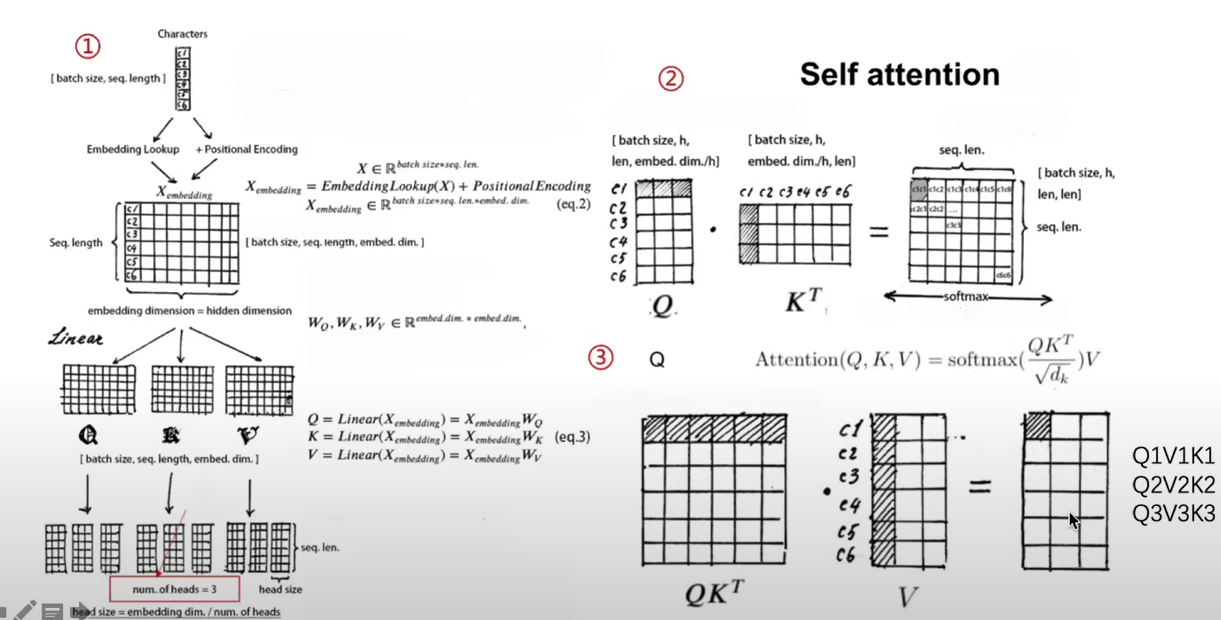
上图就是一个多头注意力机制的原理图示。我们先尝试从数学的角度建模这个模块(真的很好理解、初中数学水平):
我们考虑一个输入
其中,value矩阵,
注意:这里的softmax操作是对矩阵的每一行进行的,
最后我们将多个头的注意力加权合并便得到最终这一层attention的输出:
其中,
我们先忽略上面的偏置项
其实形象地,我们不难发现上述式子展开后的每一项都对应着多层注意力网络的一条可行路径(见下图。
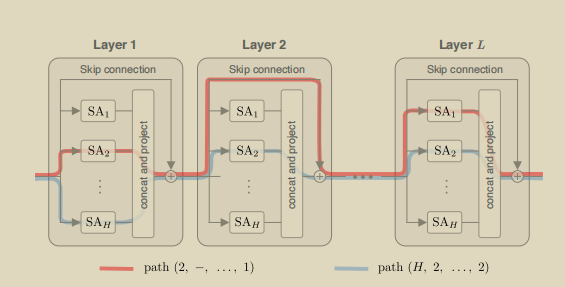
相信看完上述的描述之后,你肯定对线性LLM流行的多头注意力机制有了一个较为细致的了解了吧(不确信
pure attention collapse rank 现象?
注意力降智降秩机制其实描述的是这样的事情:随着大模型层数的增加,如果我们简单的使用注意力层的堆叠,那么最后面的输出矩阵毕竟谁都不希望看到自己的Chatbot只会说"啊对对对对对、啊错错错错错错错"吧。后面两个小节我们会分别从数学上证明这种现象和提出这种现象的解决方法
Mathematics Proof of Rank-Collapsing in pure ATTETION
首先我们需要先定义一个残差,来衡量一个矩阵和秩①矩阵的相似程度,我们定义的残差如下:
不难验证,一个矩阵如果越越接近于秩①矩阵的话残差是越小的。并且从残差的定义来看(
先来看单个头的单层注意力的情况
对于单个头的一层注意力
我们先来证明如下结论:
其中
由之前(2)式子的推导我们有:
我们引入记号
从而我们的注意力矩阵
我们再一次使用
$$
我们设
$D矩阵的相关附录见Appendix的part1;
😤😤😤不等式那一步我也没太看懂作者的意图,D是啥东西作者也没提,矩阵直接比较大小好像就是每个ij位置的元素对应比较。先硬着头皮看下去罢😤😤😤
从而我们有:
在此处
在上述步骤中我们使用了
通过类似的分析过程我们同样可以得到
结合上述两步推导过程我们有:
Appendix
Lemma-1
引理1:设row-stochastic matrix,row-stochastic matrix.(for
some matrix
成立,其中对角矩阵
后记


Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .




