
毕业设计
经过和导师的沟通之后,最终选定大模型压缩作为我的毕业设计主题
基础常用的量化、剪枝、知识蒸馏等技术的原理本文不再赘述...
文献阅读阶段
dejavu 基于上下文稀疏性的动态剪枝
【2024.10.27】
dejavu基于MHA、mlp 上下文稀疏性(contextual sparsity)的动态预测剪枝
简介
何为所谓上下文稀疏性?根据文章作者的想法,大语言模型虽然具有很深很深的层次结构和参数量,但是对于每一部分特定的输入发挥作用/被激活的却只有极少比例的参数(主要分为MHA类和MLP类两类验证)。这其实是相当符合直觉的假设,每次人脑做推理时对于给定的输入,大脑也只有少量神经元(突触)会被激活,而不是一思考整个大脑都被激活(什doge、
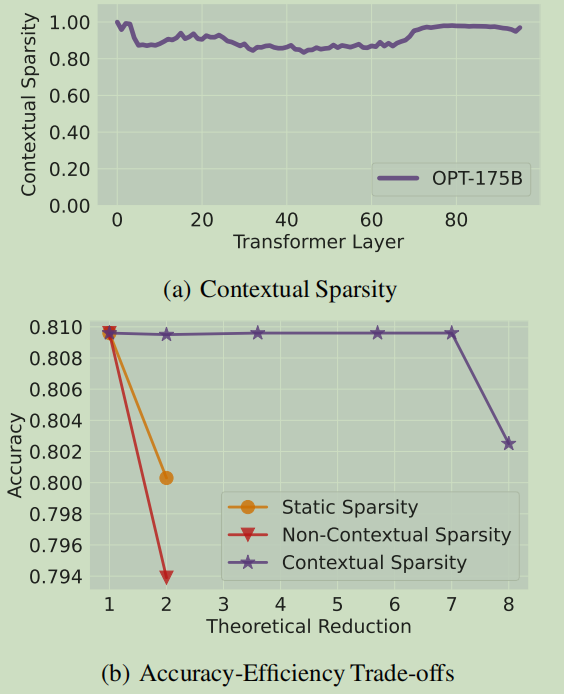
从上图中不难发现,模型中的上下文稀疏性相当显著。原文中的说法是:small、 input-dependent sets of attention heads and MLP parameters that yield approximately the same output as the dense model for a given input, can address these issues.
并且经过作者们实验验证,这样的sparsity can be accurately predicted. 作者设计另一种叫做dejavu的系统对于每一层来动态的根据输入来预测哪些参数可以被剪切。同时实现了在硬件上的并行化处理。代码地址
意义:
之前提出的模型压缩方法总是存在缺陷:(1)基于传统的剪枝方法难以在模型大小和保持效果上达到一个较好的权衡(2)之前的模型压缩方法一般是task-depandet,也就是说只能在某些特定任务下达到比较好的效果(3)有研究表明:lottery ticket hypothesis(地址)表明 iterative
pruning方法一般只适用于规模较小的模型。(4)非结构化稀疏性在加速上存在硬件困难well-known
difficulty with modern hardware;Hooker,2021
问题建模:
- MLP层的稀疏化:
考虑一个MLP的连续的两个线性层
那么原始的MLP层的输出为:
现在为了充分地利用上上下文稀疏性质,我们就决定对中间一次
其中
- MHA的稀疏化:
根据原文中的说法:假设

可见问题的关键都在于如何高效的寻找
、
实现预测
为了在预测的时候无需加载MLP、MHA层的高维的参数;论文中决定对于每一层MLP、MHA层都训练一个较小的双全连接层模型来预测哪些参数是应该被激活的。

Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .



