
月之森点子系列:設計月之森編程語言

月之森点子王最近有点无聊
Soyo最近实在是有点无聊,空虚之中她想起来了她大学期间学的最差的一门专业课——编译原理;(虽然老师讲课水平就是一坨)但是她还是打算弥补一下相关知识的欠缺。
看看月之森點子王蓑魷如何從數學和符號分析的角度形式化分析程序語言?
什么是形式语言(形式文法?
在形式语言理论中, 文法 (formal grammar)是形式语言中字符串的一套产生式规则(production rule)。这些规则描述了如何用语言的字母表 "字母表 (计算机科学)")生成符合句法(syntax)的有效的字符串。文法不描述字符串的含义,也不描述在任何上下文中可以用它们做什么——只描述它们的形式。
形式语言理论是应用数学的一个分支,是研究形式文法和语言的学科。它在理论计算机科学、理论语言学、形式语义学、数理逻辑等领域有着广泛的应用。形式文法是从一个“开始符号”出发的一套重写字符串的规则。因此,文法通常被认为是语言生成器。然而,它有时也可以用作“识别器”(计算机学中的一种函数,用于确定给定字符串是否属于该语言,是否为语法错误)的基础。形式语言理论使用另一个理论来描述识别器,也就是自动机理论。在语言中描述话语含义的第一步就是把它分解成若干部分,然后观察它经过分析后的形式(在计算机科学中被称为分析树,在生成文法中被称为深层结构)。
文法主要由一组变换字符串的规则组成。(如果它只包含这些规则,那么它就是一个半图厄系统。)要在该语言中生成字符串,首先需要一个只包含一个开始符号的字符串。然后按任意顺序应用 产生式规则 ,直到生成既不包含起始符号也不包含指定非终结符号的字符串。
比如下面这个例子:
假设我们的终结符字母表仅仅包含
那么我们从 S 开始,选择一个规则。如果我们选择规则1,我们将获得字符串 aSb 。如果我们再次选择规则1,我们用 aSb 替换 S ,得到字符串 aaSbb 。如果我们现在选择规则2,我们将 S 替换为 ba 并获得字符串 aababb ,然后就完成了。我们可以用符号将这一系列选择写得更简短:
文法的形式化定义
乔姆斯基首次提出生成语法的形式化理论,其中文法由以下部分组成:
寓意开始符号,
关于生成式文法的一些数学构造过程的定义:
- 文法
的二元关系 读作“ 的一步直接推导”定义为:
- 关系
读作“ 经过0或者更多次推导”定义为 的自反传递闭包 - 句型是指可以由开始符号
经过有限步推导得到的 的一个成员;或者更形式化的描述为 的其中一个元素,不包含非终结符号的句型称作句子。 称作 定义的语言,写作 .
Chomsky谱系:乔姆斯基范式
1956年喬姆斯基首次將生成式文法形式化定義出來的時候,他順便將它們分為了現在稱之為喬姆斯基譜係(Chomsky hierarchy)的四種類型。其中最應該受到關註的是其中的2形:上下文無關文法和3形:正則文法。
我們將要在下面的內容中詳細介紹之。
!蓑魷剪切線!
🧠上下文无关文法🧠
在计算机科学与技术中,如果一个形式文法
一个更加形式化的定义如下,上下文无关文法
这其中
是文法 所涉及的所有"非终结"符或记号的有限集合,它代表在句子中不同类型的短语或者子句。 是文法 所涉及的所有"终结"记号的有限集合, ,她构成每个句子的实际内容, 就比如每句话的每个字母寓意 start是开始记号,表示整个句子或者整个程序,。 是从 到 的一对多或者一对一的生成关系。
上下文无关文法重要的原因在于它们拥有足够强的表达力来表示大多数程序设计语言的语法;实际上,几乎所有程序设计语言都是通过上下文无关文法来定义的。
如何識別一個文法是否是上下文無關文法?
這裡不得不談我們的Earley算法在
正則文法
在正則文法中,左侧仍然只是一个非终结符号,但右侧也受到限制。右侧可以是空字符串,也可以是单个终结符号,或者是后跟非终结符号的单个终结符号,但不能是其他符号。
形式化的定義如下:正則文法是產生式規則取下述形式的一種文法
正则语言类中的语言也可以由有限状态自动机或正则表达式来表达。
設計一個屬於自己的編程語言和編譯器
如果我們想要設計一個屬於自己的編程語言,那麼我們就需要設計這門語言所對應的編譯器,如果你想知道編譯器是幹什麼工作的,請參考這篇文章.
一個編譯器包含哪些組成成分??

就如同上圖中所展示的,一個傳統意義上的編譯器例如C語言編譯器通常包含前端、優化器以及後端三個組成部分:
- 編譯器前端:任務是解析源碼、檢查語法錯誤、語法分析、語義分析。主要任務是構建一個抽象語法樹
,來描述輸入的代碼(其實這部分的工作主要就是我們形式語言的任務)。 - 優化器:使用各種技巧來優化代碼的性能,比如消解冗餘運算。
- 編譯器後端:真正的代碼生成器,負責將代碼映射到目標指令集合。一個編譯器後端的工作並不輕鬆,通產包含——指令選取、寄存器分配、指令調度等
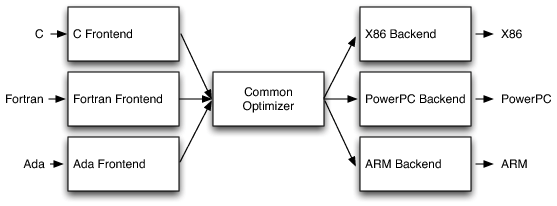
总结来说,前端+优化器+后端的结构有三大好处:灵活程度高,组件复用率高,维护成本低。知名的編譯器架構有LLVM...
程序结构解析(Parse过程)
一个简单的程序示例:
1 | func sayHello(){ |
这个程序无非就是定义另一个函数然后调用它就完了;一個程序代碼無非就是一個文本,我們處理它可以先將其看做一個tokens數組來進行處理,這個數組每個元素是一個token或者說單詞,分別是func、sasayHello、左右括號這些,他們是程序的最小處理單元,最後一個token是EOF文件結束符。如下圖所示:

解析,英文叫做 Parse,是指读入程序,并形成一个计算机可以理解的数据结构的过程。能够完成解析工作的程序,就叫做解析器(Parser),它是编译器前端的组成部分之一。那么,什么数据结构是计算机能够理解的呢?很简单,其实就是一棵树,这棵树叫做抽象语法树,英文缩写是 AST(Abstract Syntax Tree)。针对我们的例子,这棵 AST 是下面的样子:
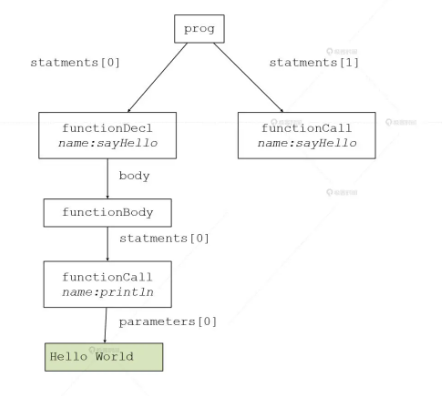
其實這棵樹同樣完整的描述了我們原來代碼中的信息:
- 根節點代表了整個程序。
- 根節點兩個子節點無非就是一個函數定義節點和一個函數調用節點。
- 函數定義節點包含了函數名稱和函數體,同時應該給出參數列表。
總而言之,我們解析器的工作就是將讀取的Tokens串轉化為一顆
首先我們需要一個將tokens串解析為AST的解析器EBNF形式化定義如下:
使用產生式規則可以如此定義:
如何代碼層面實現 ParseProg?按照以下生成規則:
$$
$$
1 |

Use this card to join the candyhome and participate in a pleasant discussion together .
Welcome to Akilar's candyhome,wish you a nice day .



